
Что такое «управление конфигурацией»
Сайты это не только код, но и инфраструктура для их запуска. В первую очередь, в нее входят сервера, на которых крутится код, база данных и различные вспомогательные системы. Иногда все это помещается на один сервер, в более сложных ситуациях количество серверов измеряется тысячами, а для обслуживания таких систем привлекаются целые команды инженеров (разного рода администраторов). Независимо от размера сайта, проблемы обслуживания инфраструктуры у всех очень похожие. Поговорим об одной конкретной – настройке сервера.
Существуют подходы, которые позволяют избежать прямого взаимодействия с инфраструктурой. В рамках статьи они не рассматриваются, но знать про них полезно. К ним относятся: классические хостинги с предустановленным софтом, serverless, хостинги статических сайтов, PaaS решения и kubernetes (и его аналоги)
В подавляющем большинстве случаев, сервера арендуются у хостинговых компаний, таких как DigitalOcean или AWS. Делается это за 5 минут нажатием буквально нескольких кнопок. Нас попросят выбрать характеристики сервера, операционную систему и датацентр, в котором он будет развернут. В результате, мы получаем машину (виртуальную), с предустановленной операционной системой и ip-адресом для входа по ssh.
Новая машина содержит только основную операционную систему с небольшим набором предустановленных программ. Перед тем как запустить на ней какой-то сервис, например, обычный сайт, понадобится установить дополнительные пакеты. Набор пакетов зависит от стека технологий, на котором он написан. Если сайт "завернут" в Docker, то настройка значительно упрощается и сводится к установке самого Docker. В остальных случаях придется потратить какое-то время на донастройку и конфигурирование. Помимо пакетов, часто требуется настраивать саму систему, менять конфигурационные файлы, права на файлы и директории, создавать пользователей и так далее:
# Как это могло бы быть
# Сервер на Ubuntu
# Заходим на удаленную машину
ssh root@ipaddress
# Создание пользователя для деплоя
# Где-то здесь копируются ssh ключи
sudo adduser deploy
sudo apt install curl
# установка Node.js
curl -fsSL https://deb.nodesource.com/setup_16.x | sudo -E bash -
sudo apt install nodejs
# установка и настройка Nginx
sudo apt install nginx
vim /etc/nginx/default.conf
# Формирование структуры директорий для сервиса
mkdir -p /opt/hexlet/versions/
Процесс первоначальной настройки занимает часы и даже дни. Постоянно придется что-то подкручивать, донастраивать и устанавливать. Цикл повториться снова, когда понадобится перейти на новые версии пакетов. Снова придется заходить на сервер, вспоминать что и где настраивалось и как мягко обновиться ничего не сломав. В чем проблема ручной настройки?
Сервера могут умирать и делать это внезапно. Сколько времени уйдет на "раскатку" нового сервера? Практически столько же времени, сколько было потрачено первый раз. Порядок действий и нужные настройки просто никто не вспомнит даже через неделю после настройки, что уже говорить если прошли месяцы. Более того, вдруг тот кто изначально это делал уже не работает в компании или находится в отпуске. Что тогда? Придется долго извиняться перед пользователями за длительный простой и хорошо если бизнес от этого пострадает не сильно.
Переустановка сервера не обязательно связана с какими-то форс-мажорными обстоятельствами. В компаниях с хорошей инженерной культурой, сервера меняются на регулярной основе. Как минимум это важно для безопасности. Операционные системы содержат уязвимости, которые закрываются новыми пакетами или версиями. Следить за этим довольно сложно, поэтому проще регулярно освежать инфраструктуру. С другой стороны, обновление сервера может легко сломать рабочее приложение и вызвать простой в работе. Единственный способ гарантировать беспрерывную работу во время обновления – поднимать рядом еще один сервер и настраивать его. Затем сервис просто выкатывается на новый сервер, а старый выключается.
Автоматизация
Хорошо бы было автоматизировать настройку сервера. Для этого существует несколько подходов, которые мы рассмотрим ниже.
Bash-скрипты
В простейшем случае для этого достаточно обычного Bash-скрипта, в который последовательно добавляются команды, которые ранее мы запускали руками. Затем все сводится к копированию скрипта на сервер и запуску:
# Копирование на сервер с помощью scp
scp mybashscript.sh root@ipaddress:~/
# Заходим на сервер и запускаем скрипт
ssh root@ipaddress
sh ~/mybashscript.sh
Если перенести команды в bash-скрипт "как есть", без модификации, то, скорее всего, нам придется постоянно следить за выводом и не забывать подтверждать установку пакетов, так как это поведение по умолчанию:
➜ ~ apt install golang
The following additional packages will be installed:
golang-1.13 golang-1.13-doc golang-1.13-go golang-1.13-race-detector-runtime golang-1.13-src golang-doc golang-go
Need to get 63.5 MB of archives.
After this operation, 329 MB of additional disk space will be used.
Do you want to continue? [Y/n] # Скрипт останавливается и ждет ответа
Автоматическое "да" добавляется опцией -y. У других команд свои опции для подавления взаимодействия с пользователем. Придется их все учесть.
apt install -y golang
Другая проблема серьезнее, она связана с понятием "идемпотентность". Что будет если выполнить команду создания директории два раза?
mkdir /hexlet
mkdir /hexlet # ?
Команда завершится с ошибкой, она не идемпотентна. То есть последовательные вызовы одной и той же команды приводят к разному результату. Идемпотентность для настройки сервера очень важна. Иначе повторный запуск скрипта настройки завершится с ошибкой. А повторные запуски нужны, например в случае отладки самого скрипта, когда мы его только пишем и проверяем как он работает. В случае с командой mkdir идемпотентности добиться легко, достаточно добавить флаг -p:
mkdir -p /hexlet
mkdir -p /hexlet # ошибки не будет
Но, к сожалению не все команды поддерживают такую возможность. Для многих ситуаций, идемпотентность нужно обеспечивать самостоятельно, что резко усложнит скрипт. Из простого набора команд он превратиться в реальный код с условными конструкциями. И в какой-то момент разбираться в нем станет крайне сложно. Через это проходили многие, особенно раньше, когда не было альтернативы.
Но дело не только в идемпотентности. Часть задач, которые легко делались руками, становятся сложными в автоматизации. Представьте, что для изменения конфигурации нужно поправить конкретную строчку внутри файла. Как это легко сделать с помощью bash? Никак, придется либо полностью заменять файл копируя всего содержимое в bash-скрипт (или рядом с ним), либо использовать, что-то вроде sed для точечной замены строки.
И последнее, но очень важное ограничение. Bash-скрипт нужно доставить на сервер самостоятельно. И если для одного сервера это еще как-то можно автоматизировать, то для нескольких "раскатка" скрипта становится проблемой. Становится важно делать это параллельно иначе настройка растягивается на часы даже в случае полной автоматизации. Добавьте сюда разные сервера со своими скриптами, которые отличаются от других.
На этом этапе bash-скрипты перестают помогать, нужно придумывать что-то еще. Так стали появляться специализированные инструменты для конфигурирования серверов. Одними из первых были проекты Chef и Puppet. Сейчас же, наибольшую популярность приобрел Ansible, который значительно проще в освоении и использовании.
Ansible
Система управления конфигурацией (серверов), которая решает все проблемы описанные выше и, даже больше, может использоваться не только для настройки, но и для деплоя, то есть установки и запуска сервиса. Для установки Ansible воспользуйтесь одним из предложенных способов
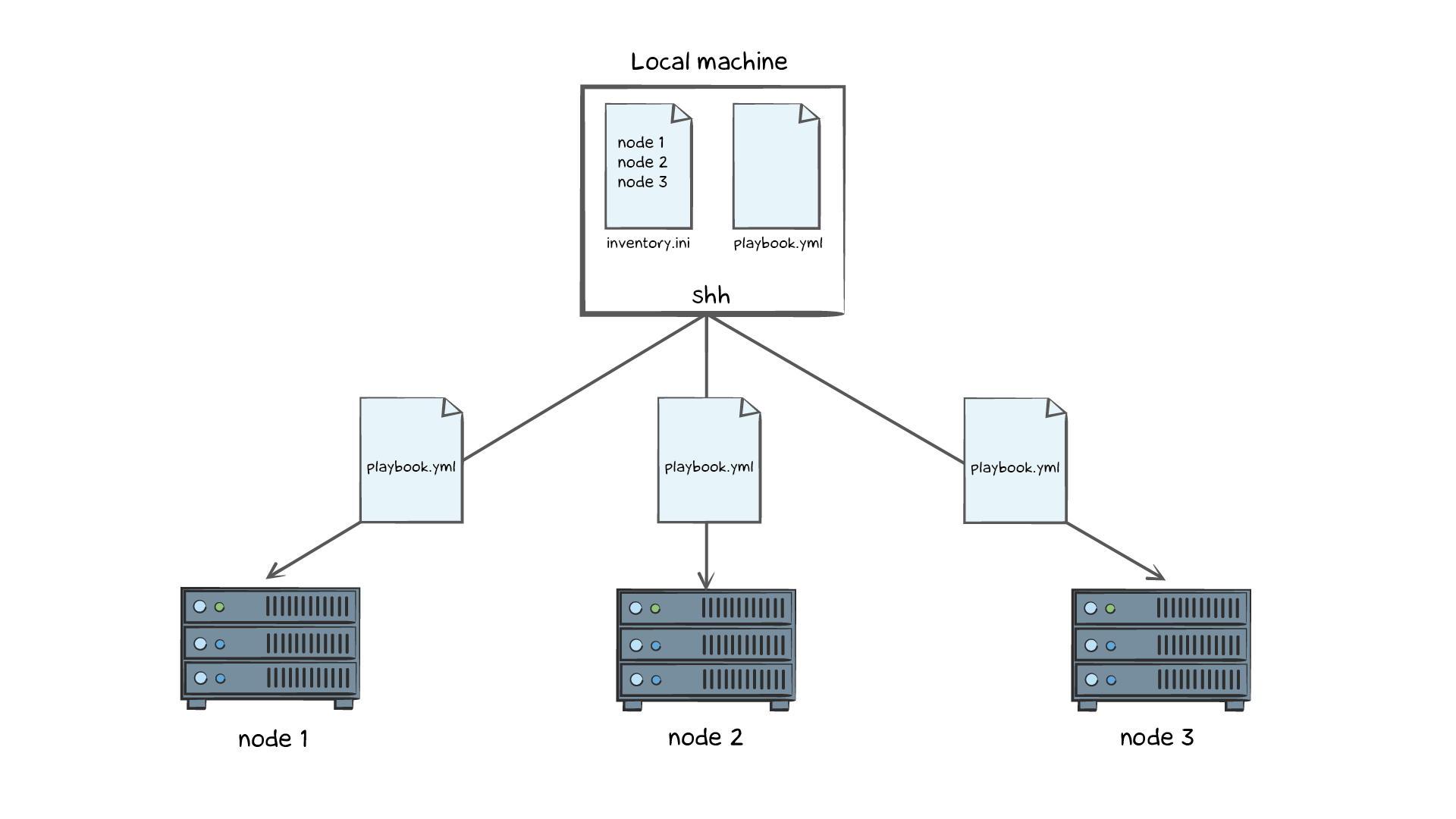
В минимальном виде, Ansible конфигурация выглядит как два файла, один – описание серверов, второй – команды, которые мы хотим выполнить. Ansible сам подключается к удаленным серверам и выполняет необходимые команды. Главное дать доступ к этим серверам, например с помощью ssh-ключей.
Описание серверов хранится в файле inventory.ini. Ansible использует его для определения машин, на которые нужно выполнить установку.
; адрес машины, которую настраиваем
; для простоты говорим Ansible использовать локальный компьютер
127.0.0.1 ansible_connection=local
Команды настройки сервера записываются в файлы называемые плейбуками. Плейбуки создаются в формате yaml под любым именем. Например playbook.yaml:
# hosts – означает группу машин, на которой нужно выполниться
# all – означает все описанные в inventory.ini
- hosts: all
tasks: # набор команд которые нужно выполнить
- ansible.builtin.file: # file – управляет файлами и директориями
name: /tmp/ansible_was_here
state: touch # выполнит команду touch если файла не существует. И – идемпотентность
Файловая структура может выглядеть так:
tree # вывод содержимого директории
.
├── inventory.ini
└── playbook.yaml
Теперь запускаем:
# Запуск Ansible идет на локальной машине!
# Запускать нужно в той же директории, где созданы файлы
# -i означает inventory.ini
# https://github.com/hexlet-boilerplates/ansible
ansible-playbook -i inventory.ini playbook.yaml
PLAY [Server Setup] ***********************************************************************************************************
TASK [Gathering Facts] ********************************************************************************************************
ok: [127.0.0.1]
TASK [file] *******************************************************************************************************************
changed: [127.0.0.1]
PLAY RECAP ********************************************************************************************************************
127.0.0.1 : ok=2 changed=1 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
Вывод говорит о том, что плейбук успешно выполнен. В результате в директории /tmp окажется файл ansible_was_here. Повторный запуск плейбука тоже закончится успешно, но из вывода будет видно, что он не сделает никаких изменений, так как Ansible сам обеспечивает идемпотентность. В данном случае, он проверит наличие файла и пропустит команду если файл существует. Если в inventory.ini указать несколько ip-адресов, то Ansible выполнит плейбук на каждом из них, причем сделает это параллельно. Единственное о чем нужно не забыть – добавить ssh-ключи на эти машины, иначе Ansible не сможет до них достучаться.
Что из себя представляет плейбук? Главное внутри него – набор задач (tasks), которые мы хотим выполнить. В отличии от bash-скрипта, задачи это не просто bash-команды. На каждую задачу в Ansible встроен модуль для работы с определенной частью системы. Например внутри Ansible есть модули для работы с git, пакетными менеджерами, файлами и тому подобным. Всего их сотни на все случаи жизни. Именно благодаря готовым интеграциям, Ansible знает как работают те или иные части системы, что позволяет добавить нужные проверки для обеспечения идемпотентности. Пара примеров:
tasks:
# Установка postgresql
- name: Ensure postgresql is at the latest version
ansible.builtin.apt: # модуль apt
name: postgresql
state: latest
# Запуск postgresql
- name: Ensure that postgresql is started
ansible.builtin.service: # модуль service
name: postgresql
state: started # запускаем если не запущен
Как видите, Ansible достаточно прост для начала, при этом у него много возможностей, которые можно изучать по мере погружения и усложнения инфраструктуры.
Итого
Управление конфигурацией, в современном мире, выполняется с помощью специализированных программ, которые умеют подключаться к удаленным серверам, параллельно настраивать их обеспечивая идемпотентность операций. При таком подходе важно перестать настраивать сервера напрямую. Любые изменения теперь должны делаться через инструмент автоматизации, иначе все вернется к изначальным проблемам. Управление конфигурацией через код повышает взаимозаменяемость людей, позволяет легко отслеживать изменения просто просматривая историю git, подключать других членов команды к управлению инфраструктурой.